Publications
2025
- SEC
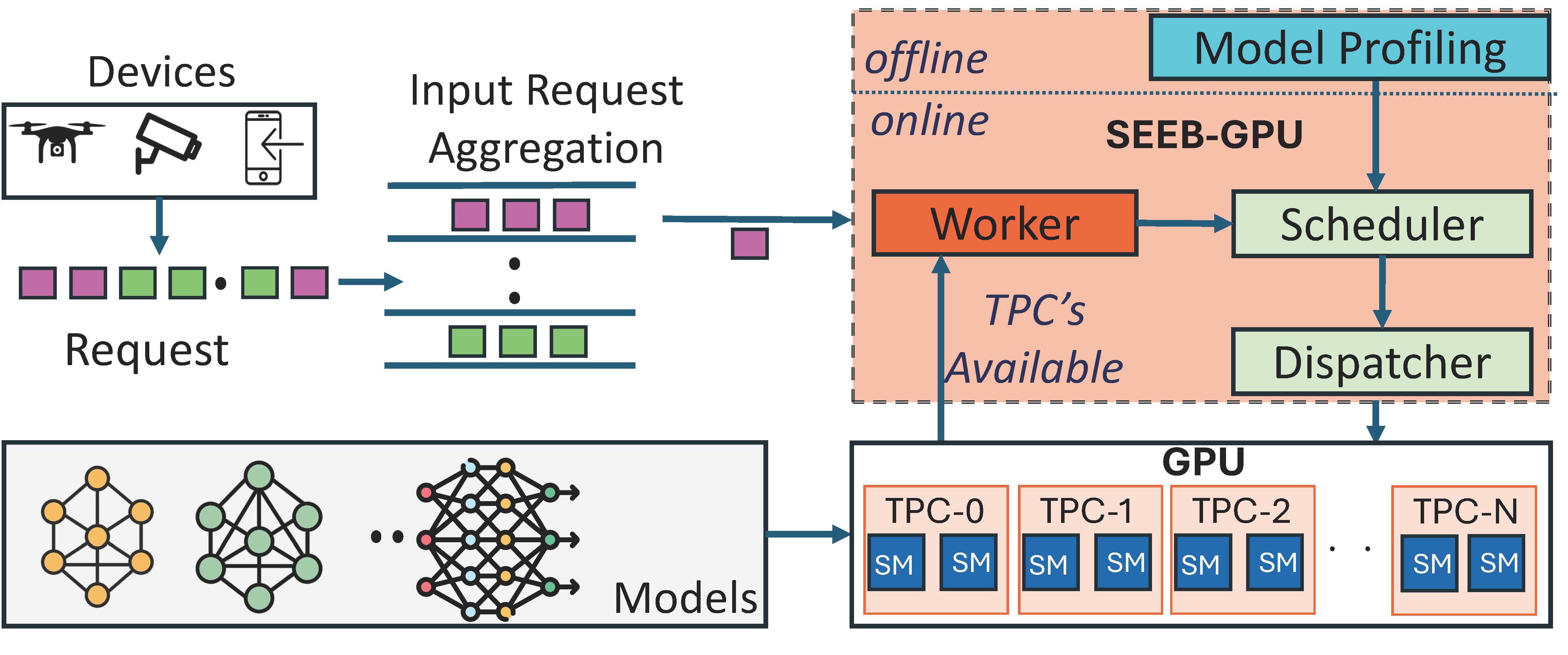 SEEB-GPU: Early-Exit Aware Scheduling and Batching for Edge GPU InferenceSrinivasan Subramaniyan, Rudra Joshi, Xiaorui Wang, and Marco BrocanelliIn Proceedings of the Tenth ACM/IEEE Symposium on Edge Computing, 2025
SEEB-GPU: Early-Exit Aware Scheduling and Batching for Edge GPU InferenceSrinivasan Subramaniyan, Rudra Joshi, Xiaorui Wang, and Marco BrocanelliIn Proceedings of the Tenth ACM/IEEE Symposium on Edge Computing, 2025@inproceedings{10.1145/3769102.3772715, author = {Subramaniyan, Srinivasan and Joshi, Rudra and Wang, Xiaorui and Brocanelli, Marco}, title = {SEEB-GPU: Early-Exit Aware Scheduling and Batching for Edge GPU Inference}, year = {2025}, isbn = {9798400722387}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3769102.3772715}, doi = {10.1145/3769102.3772715}, booktitle = {Proceedings of the Tenth ACM/IEEE Symposium on Edge Computing}, articleno = {9}, numpages = {16}, keywords = {edge inference, GPU resource management, early-exit DNNs}, series = {SEC '25}, } - IPCCC
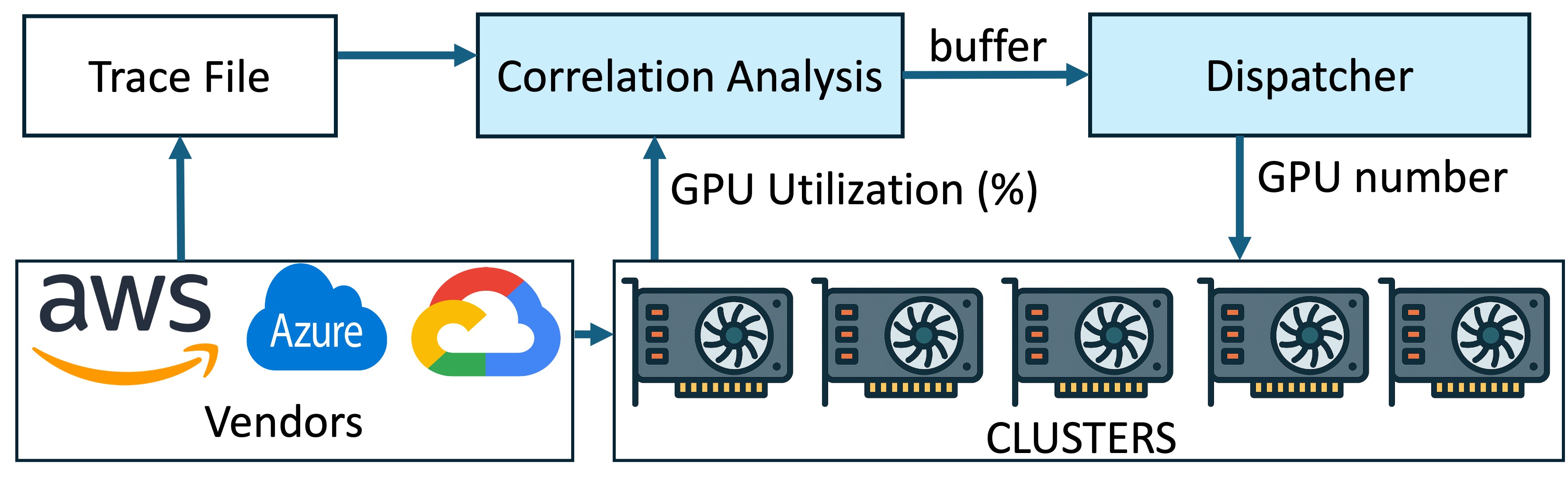 Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data CentersSrinivasan Subramaniyan and Xiaorui WangIn Proceedings of the 44th IEEE International Performance Computing and Communications Conference, 2025
Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data CentersSrinivasan Subramaniyan and Xiaorui WangIn Proceedings of the 44th IEEE International Performance Computing and Communications Conference, 2025Recieved the Best Paper Runner up award
@inproceedings{CorrGPU, author = {Subramaniyan, Srinivasan and Wang, Xiaorui}, title = {Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data Centers}, year = {2025}, publisher = {IEEE}, url = {https://par.nsf.gov/biblio/10652009}, booktitle = {Proceedings of the 44th IEEE International Performance Computing and Communications Conference}, } - ICPP
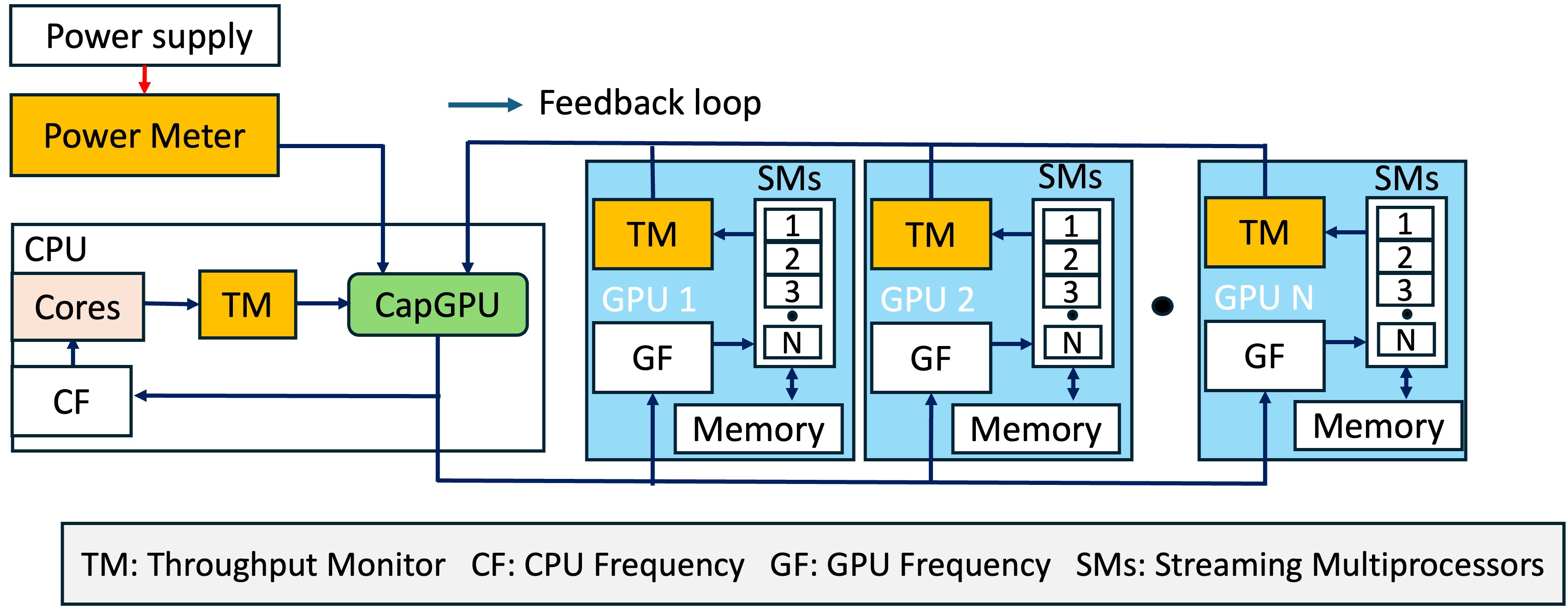 Power Capping of GPU Servers for Machine Learning Inference OptimizationSrinivasan Yuan Ma and Xiaorui WangIn The 54th International Conference on Parallel Processing, 2025
Power Capping of GPU Servers for Machine Learning Inference OptimizationSrinivasan Yuan Ma and Xiaorui WangIn The 54th International Conference on Parallel Processing, 2025@inproceedings{CapGPU, author = {Yuan Ma, Subramaniyan, Srinivasan and Wang, Xiaorui}, title = {Power Capping of GPU Servers for Machine Learning Inference Optimization}, year = {2025}, publisher = {IEEE}, url = {https://par.nsf.gov/biblio/10652010}, booktitle = {The 54th International Conference on Parallel Processing}, } - EMSOFT
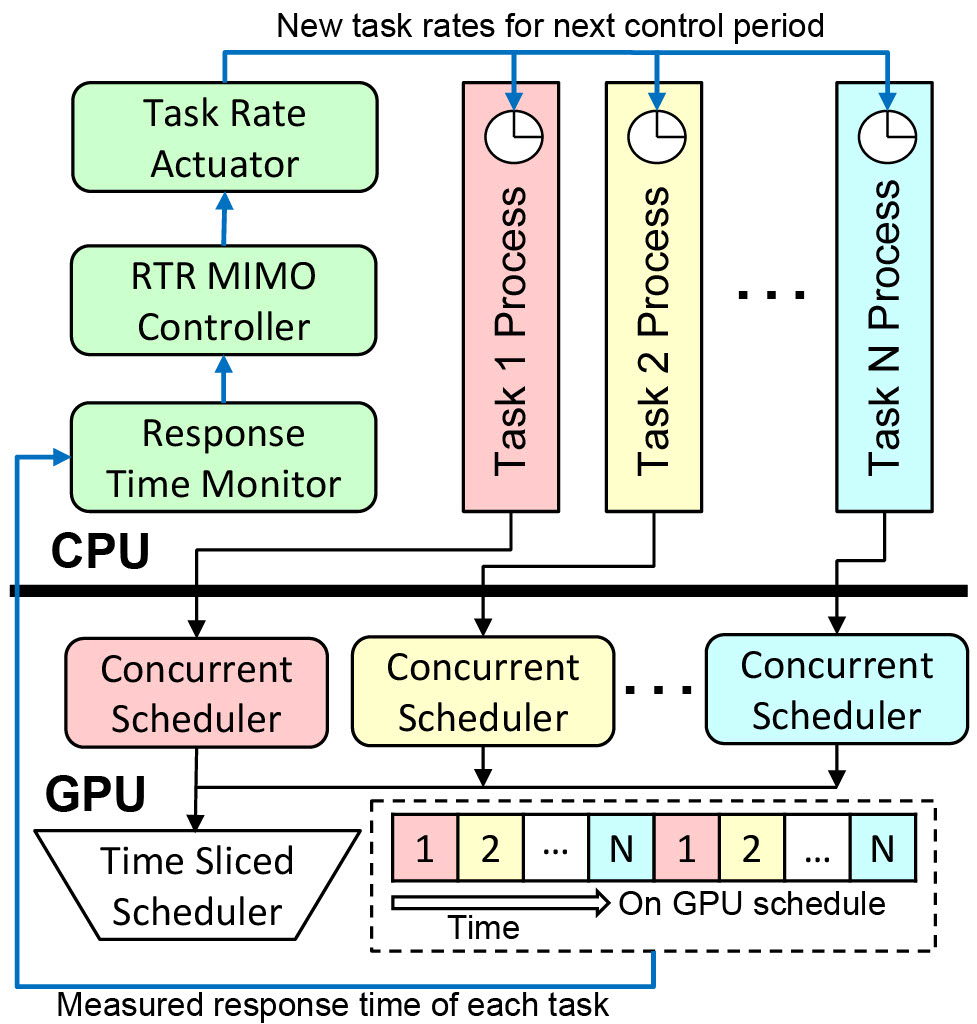 FC-GPU: Feedback Control GPU Scheduling for Real-Time Embedded SystemsSrinivasan Subramaniyan and Xiaorui WangACM Transactions on Embedded Computing Systems, Sep 2025
FC-GPU: Feedback Control GPU Scheduling for Real-Time Embedded SystemsSrinivasan Subramaniyan and Xiaorui WangACM Transactions on Embedded Computing Systems, Sep 2025Recieved the Outstanding Paper award for FC-GPU at ESWEEK 2025
GPUs have recently been adopted in many real-time embedded systems. However, existing GPU scheduling solutions are mostly open-loop and rely on the estimation of worst-case execution time (WCET). Although adaptive solutions, such as feedback control scheduling, have been previously proposed to handle this challenge for CPU-based real-time tasks, they cannot be directly applied to GPUs, because GPUs have different and more complex architectures and so schedulable utilization bounds cannot apply to GPUs yet. In this article, we propose FC-GPU, the first feedback control GPU scheduling framework for real-time embedded systems. To model the GPU resource contention among tasks, we analytically derive a multi-input–multi-output (MIMO) system model that captures the impacts of task rate adaptation on the response times of different tasks. Building on this model, we design a MIMO controller that dynamically adjusts task rates based on measured response times. Our extensive hardware testbed results on an NVIDIA RTX 3090 GPU and an AMD MI-100 GPU demonstrate that FC-GPU can provide better real-time performance even when the task execution times significantly increase at runtime.
@article{10.1145/3761812, author = {Subramaniyan, Srinivasan and Wang, Xiaorui}, title = {FC-GPU: Feedback Control GPU Scheduling for Real-Time Embedded Systems}, year = {2025}, issue_date = {September 2025}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, volume = {24}, number = {5s}, issn = {1539-9087}, url = {https://doi.org/10.1145/3761812}, doi = {10.1145/3761812}, journal = {ACM Transactions on Embedded Computing Systems}, month = sep, articleno = {155}, numpages = {25}, keywords = {GPU scheduling, real-time systems, embedded systems, feedback control}, }
2024
- ICDCS
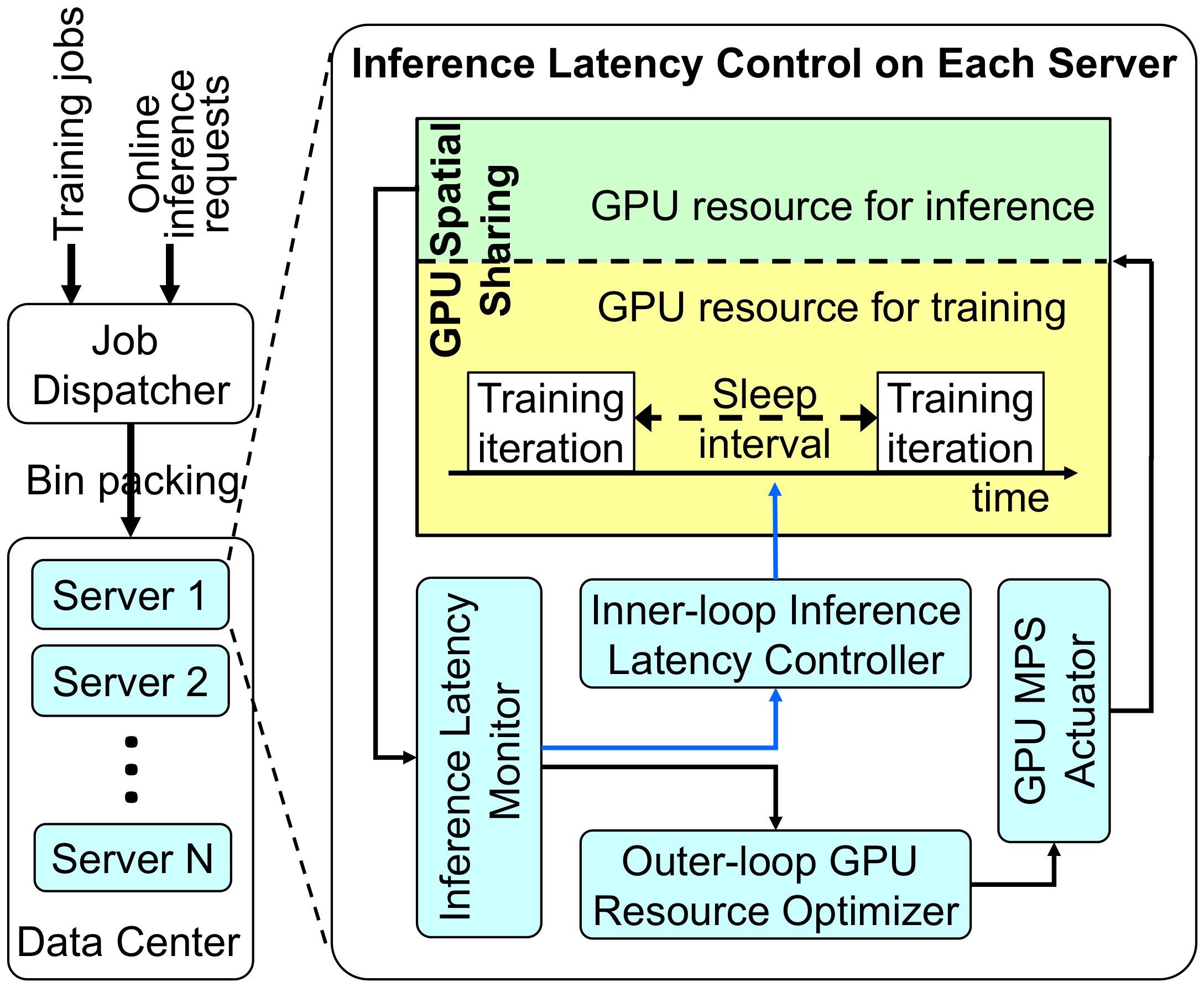 Latency-Guaranteed Co-Location of Inference and Training for Reducing Data Center ExpensesGuoyu Chen, Srinivasan Subramaniyan, and Xiaorui WangIn 2024 IEEE 44th International Conference on Distributed Computing Systems (ICDCS), Sep 2024
Latency-Guaranteed Co-Location of Inference and Training for Reducing Data Center ExpensesGuoyu Chen, Srinivasan Subramaniyan, and Xiaorui WangIn 2024 IEEE 44th International Conference on Distributed Computing Systems (ICDCS), Sep 2024Today’s data centers often need to run various machine learning (ML) applications with stringent SLO (Service-Level Objective) requirements, such as inference latency. To that end, data centers prefer to 1) over-provision the number of servers used for inference processing and 2) isolate them from other servers that run ML training, despite both use GPUs extensively, to minimize possible competition of computing resources. Those practices result in a low GPU utilization and thus a high capital expense. Hence, if training and inference jobs can be safely co-located on the same GPUs with explicit SLO guarantees, data centers could flexibly run fewer training jobs when an inference burst arrives and run more afterwards to increase GPU utilization, reducing their capital expenses. In this paper, we propose GPUColo, a two-tier co-location solution that provides explicit ML inference SLO guarantees for co-located GPUs. In the outer tier, we exploit GPU spatial sharing to dynamically adjust the percentage of active GPU threads allocated to spatially co-located inference and training processes, so that the inference latency can be guaranteed. Because spatial sharing can introduce considerable overheads and thus cannot be conducted at a fine time granularity, we design an inner tier that puts training jobs into periodic sleep, so that the inference jobs can quickly get more GPU resources for more prompt latency control. Our hardware testbed results show that GPUColo can precisely control the inference latency to the desired SLO, while maximizing the throughput of the training jobs co-located on the same GPUs. Our large-scale simulation with a 57-day real-world data center trace (6500 GPUs) also demonstrates that GPU Colo enables latency-guaranteed inference and training co-location. Consequently, it allows 74.9 % of GPUs to be saved for a much lower capital expense.
@inproceedings{gpucolo2024icdcs, author = {Chen, Guoyu and Subramaniyan, Srinivasan and Wang, Xiaorui}, booktitle = {2024 IEEE 44th International Conference on Distributed Computing Systems (ICDCS)}, title = {Latency-Guaranteed Co-Location of Inference and Training for Reducing Data Center Expenses}, year = {2024}, url = {https://ieeexplore.ieee.org/abstract/document/10630927}, paper = {Latency-Guaranteed_Co-Location_of_Inference_and_Training_for_Reducing_Data_Center_Expenses.pdf}, pages = {473-484}, keywords = {Training;Data centers;Graphics processing units;Machine learning;Throughput;Hardware;Servers;Machine learning;data center;inference;latency;GPU;co-location}, doi = {10.1109/ICDCS60910.2024.00051}, }
2023
- IPDPSWOptiCPD: Optimization For The Canonical Polyadic Decomposition Algorithm on GPUsSrinivasan Subramaniyan and Xiaorui WangIn 2023 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Sep 2023
@inproceedings{10196662, author = {Subramaniyan, Srinivasan and Wang, Xiaorui}, booktitle = {2023 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW)}, title = {OptiCPD: Optimization For The Canonical Polyadic Decomposition Algorithm on GPUs}, year = {2023}, pages = {403-412}, url = {https://ieeexplore.ieee.org/10196662}, keywords = {Tensors;Multicore processing;High performance computing;Optimal scheduling;Machine learning;Linear algebra;Parallel processing;CPD/PARAFAC;CPU;GPU;MTTKRP}, doi = {10.1109/IPDPSW59300.2023.00071} } - Design & TestEnabling High-Level Design Strategies for High-Throughput and Low-Power NB-LDPC DecodersSrinivasan Subramaniyan, Oscar Ferraz, M. R. Ashuthosh, and 6 more authorsIEEE Design & Test, Sep 2023
@article{9869892, author = {Subramaniyan, Srinivasan and Ferraz, Oscar and Ashuthosh, M. R. and Krishna, Santosh and Wang, Guohui and Cavallaro, Joseph R. and Silva, Vitor and Falcao, Gabriel and Purnaprajna, Madhura}, journal = {IEEE Design & Test}, title = {Enabling High-Level Design Strategies for High-Throughput and Low-Power NB-LDPC Decoders}, year = {2023}, volume = {40}, number = {1}, pages = {85-95}, url = {https://ieeexplore.ieee.org/document/9869892}, keywords = {Decoding;Codes;Symbols;Parity check codes;Data processing;Graphics processing units;Sparse matrices;NB-LDPC;FPGA;GPU;RTL;HLS}, doi = {10.1109/MDAT.2022.3202852} }
2022
- VLSIDMAPPARAT: A Resource Constrained FPGA-Based Accelerator for Sparse-Dense Matrix MultiplicationM. R. Ashuthosh, Santosh Krishna, Vishvas Sudarshan, and 2 more authorsIn 2022 35th International Conference on VLSI Design and 2022 21st International Conference on Embedded Systems (VLSID), Sep 2022
Matrix Multiplication has gained importance due to its wide usage in Deep Neural Networks. The presence of sparsity in matrices needs special considerations to avoid redundancy in computations and memory accesses. Sparsity becomes relevant in the choice of compression format for storage and memory access. In addition to compression format, the choice of the algorithm also influences the performance of the matrix multiplier. The interplay of algorithm and compression formats results in significant variations in several performance parameters such as execution time, memory, and total energy consumed. This paper presents MAPPARAT, a custom FPGA-based hardware accelerator for sparse×dense matrix multiplication. Our analysis show that the choice of the compression format is heavily dependent on sparsity of the input matrices. We present two variants of MAPPARAT based on the algorithm used for sparse×dense matrix multiplication, viz., row-wise and column-wise product. A difference in speedup of 2.5× and a difference in energy consumption by about 2.6× is seen between the two variants. We show that an intelligent choice of algorithm and compression format based on the variations in sparsity, matrix dimensions, and device specifications is necessary for performance acceleration. For identical sparse matrices, a speedup of up to 3.6× is observed, when the dense format is chosen for one of the matrices for sparsity in the range of 30% to 90%. MAPPARAT on a resource-constrained device shows performance efficiency of up to 7 GOPs-per-second-per-watt.
@inproceedings{9885949, author = {Ashuthosh, M. R. and Krishna, Santosh and Sudarshan, Vishvas and Subramaniyan, Srinivasan and Purnaprajna, Madhura}, booktitle = {2022 35th International Conference on VLSI Design and 2022 21st International Conference on Embedded Systems (VLSID)}, title = {MAPPARAT: A Resource Constrained FPGA-Based Accelerator for Sparse-Dense Matrix Multiplication}, year = {2022}, volume = {}, number = {}, pages = {102-107}, url = {https://ieeexplore.ieee.org/document/9885949}, keywords = {Performance evaluation;Deep learning;Energy consumption;Embedded systems;Redundancy;Neural networks;Very large scale integration}, doi = {10.1109/VLSID2022.2022.00031} }
2021
- COMSTA survey on high-throughput non-binary LDPC decoders: ASIC, FPGA, and GPU architecturesOscar Ferraz, Srinivasan Subramaniyan, Ramesh Chinthala, and 7 more authorsIEEE Communications Surveys & Tutorials, Sep 2021
Non-binary low-density parity-check (NB-LDPC) codes show higher error-correcting performance than binary low-density parity-check (LDPC) codes when the codeword length is moderate and/or the channel has bursts of errors. The need for high-speed decoders for future digital communications led to the investigation of optimized NB-LDPC decoding algorithms and efficient implementations that target high throughput and low energy consumption levels. We carried out a comprehensive survey of existing NB-LDPC decoding hardware that targets the optimization of these parameters. Even though existing NB-LDPC decoders are optimized with respect to computational complexity and memory requirements, they still lag behind their binary counterparts in terms of throughput, power and area optimization. This study contributes to an overall understanding of the state-of-the-art on application-specific integrated-circuit (ASIC), field-programmable gate array (FPGA) and graphics processing units (GPU) based systems, and highlights the current challenges that still have to be overcome on the path to more efficient NB-LDPC decoder architectures.
@article{ferraz2021survey, title = {A survey on high-throughput non-binary LDPC decoders: ASIC, FPGA, and GPU architectures}, author = {Ferraz, Oscar and Subramaniyan, Srinivasan and Chinthala, Ramesh and Andrade, Jo{\~a}o and Cavallaro, Joseph R and Nandy, Soumitra K and Silva, Vitor and Zhang, Xinmiao and Purnaprajna, Madhura and Falcao, Gabriel}, journal = {IEEE Communications Surveys \& Tutorials}, doi = {10.1109/COMST.2021.3126127}, volume = {24}, number = {1}, pages = {524--556}, url = {https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9606216}, year = {2021}, publisher = {IEEE}, }
2020
- SiPSPushing the Limits of Energy Efficiency for Non-Binary LDPC Decoders on GPUs and FPGAsSrinivasan Subramaniyan, Oscar Ferraz, M. R. Ashuthosh, and 6 more authorsIn 2020 IEEE Workshop on Signal Processing Systems (SiPS), Sep 2020
Signal processing hardware designers of Low-Density Parity-Check (LDPC) decoders used in modern optical communications are confronted with the need to perform multi-parametric design space exploration, targeting very high throughput (hundreds of Mbit/s) and low-power systems. This work addresses the needs of current designers of dedicated GF(2m) NB-LDPC decoders that necessitate robust approaches for dealing with the ever-increasing demand for higher BER performance. The constraints pose tremendous pressure on the on-chip design of irregular data structures and micro-circuit implementation for supporting the complex Galois field mathematics and communications of hundreds of check nodes with hundreds of variable node processors. We have developed kernels targeting GPU and FPGA (HLS and its equivalent RTL) descriptions of this class of complex circuits for comparing area, frequency of operation, latency, parallelism and throughput. Exploiting techniques such as using custom bit-widths, pipelining, loop-unrolling, array-partitioning and the replication of compute units, results in considerably faster design cycles and demands less non-recurring engineering effort. We report a throughput performance of 800 Mbps for the FPGA case.
@inproceedings{9195258, author = {Subramaniyan, Srinivasan and Ferraz, Oscar and Ashuthosh, M. R. and Krishna, Santosh and Wang, Guohui and Cavallaro, Joseph R. and Silva, Vitor and Falcao, Gabriel and Purnaprajna, Madhura}, booktitle = {2020 IEEE Workshop on Signal Processing Systems (SiPS)}, title = {Pushing the Limits of Energy Efficiency for Non-Binary LDPC Decoders on GPUs and FPGAs}, year = {2020}, pages = {1-6}, url = {https://ieeexplore.ieee.org/document/9195258}, keywords = {Field programmable gate arrays;Graphics processing units;Measurement;Kernel;Decoding;Instruction sets;Parity check codes;design space exploration;roofline model;high-throughput;parallelism;low-power;FPGAs;GPUs;RTL;HLS;NB-LDPC decoding}, doi = {10.1109/SiPS50750.2020.9195258} } - FCCMGbit/s Non-Binary LDPC Decoders: High-Throughput using High-Level SpecificationsOscar Ferraz, Srinivasan Subramaniyan, Guohui Wang, and 3 more authorsIn 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Sep 2020
It is commonly perceived that an HLS specification targeted for FPGAs cannot provide throughput performance in par with equivalent RTL descriptions. In this work we developed a complex design of a non-binary LDPC decoder, that although hard to generalise, shows that HLS provides sufficient architectural refinement options. They allow attaining performance above CPU- and GPU-based ones and excel at providing a faster design cycle when compared to RTL development.
@inproceedings{9114836, author = {Ferraz, Oscar and Subramaniyan, Srinivasan and Wang, Guohui and Cavallaro, Joseph R. and Falcao, Gabriel and Purnaprajna, Madhura}, booktitle = {2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM)}, title = {Gbit/s Non-Binary LDPC Decoders: High-Throughput using High-Level Specifications}, year = {2020}, pages = {226-226}, url = {https://ieeexplore.ieee.org/document/9114836}, keywords = {Throughput;Parity check codes;Decoding;Field programmable gate arrays}, doi = {10.1109/FCCM48280.2020.00058} } - CoIn: Accelerated CNN Co-Inference through data partitioning on heterogeneous devicesK. Vanishree, Anu George, Srivatsav Gunisetty, and 3 more authorsIn 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Sep 2020
In Convolutional Neural Networks (CNN), the need for low inference time per batch is crucial for real-time applications. To improve the inference time, we present a method (CoIn) that benefits from the use of multiple devices that execute simultaneously. Our method achieves the goal of low inference time by partitioning images of a batch on diverse micro-architectures. The strategy for partitioning is based on offline profiling on the target devices. We have validated our partitioning technique on CPUs, GPUs and FPGAs that include memory-constrained devices in which case, a re-partitioning technique is applied. An average speedup of 1.39x and 1.5x is seen with CPU-GPU and CPU-GPU-FPGA co-execution respectively. In comparison with the approach of the state-of-the-art, CoIn has an average speedup of 1.62x across all networks.
@inproceedings{9074444, author = {Vanishree, K. and George, Anu and Gunisetty, Srivatsav and Subramanian, Srinivasan and Kashyap R., Shravan and Purnaprajna, Madhura}, booktitle = {2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS)}, title = {CoIn: Accelerated CNN Co-Inference through data partitioning on heterogeneous devices}, year = {2020}, volume = {}, number = {}, pages = {90-95}, url = {https://ieeexplore.ieee.org/abstract/document/9074444}, keywords = {Performance evaluation;Graphics processing units;Field programmable gate arrays;Acceleration;Memory management;Time measurement;Computational modeling;CNN;CPU-GPU system;GPU-FPGA system;Data Partitioning;inference acceleration}, doi = {10.1109/ICACCS48705.2020.9074444} }