Srinivasan Subramaniyan
PACS Lab, ECE Dept., The Ohio State University, Columbus, Ohio, USA

805 Dreese Laboratories
2015 Neil Avenue
Columbus, Ohio 43201
I’m a Ph.D. candidate in Electrical and Computer Engineering at The Ohio State University, working in the Power-Aware Computer Systems (PACS) Lab under Dr. Xiaorui Wang.
My research focuses on GPU scheduling, computer architecture, and edge/cloud systems, with an emphasis on energy-efficient and high-performance computing. I am the author of several award-winning papers, including the Outstanding Paper Award at EMSOFT 2025 and the Best Paper Award at VLSID 2022. I am actively seeking opportunities in computer architecture, high-performance computing, and systems research, with a strong interest in developing next-generation energy-efficient computing architectures.
news
| Mar 05, 2026 | I received third place in the 2026 Graduate Hayes Forum in the College of Engineering at The Ohio State University. I was also awarded the Career Development Grant from the Council of Graduate Students (CGS) at The Ohio State University. |
|---|---|
| Jan 12, 2026 | I won first place in the College of Engineering 3MT (Three Minute Thesis) competition at The Ohio State University. |
| Dec 08, 2025 | I have passed my candidacy exam and am officially a PhD candidate. |
| Nov 22, 2025 | Excited to announce that i received the Best-paper runner up for the work “Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data Centers.” at IPCCC 2025 |
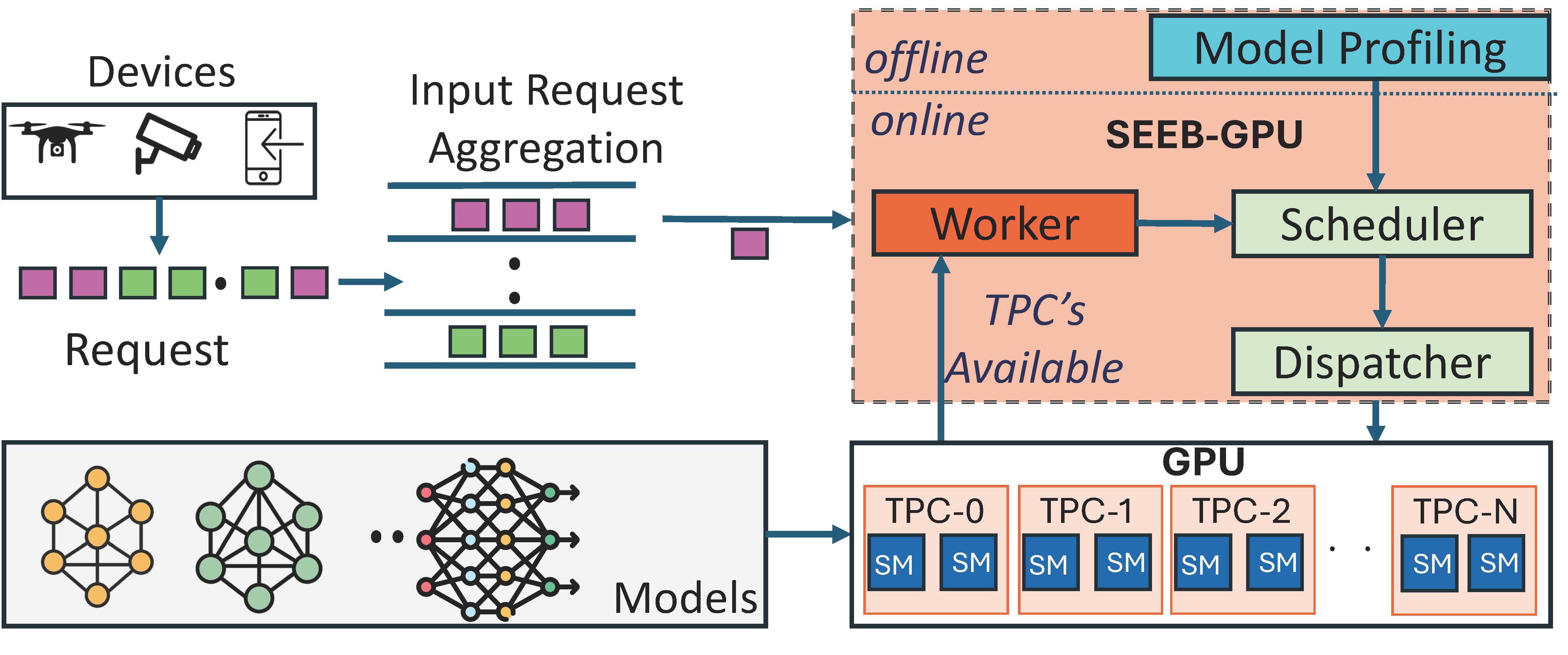
| Oct 27, 2025 | Our paper “SEEB-GPU” has been accepted for publication at SEC 2025. |
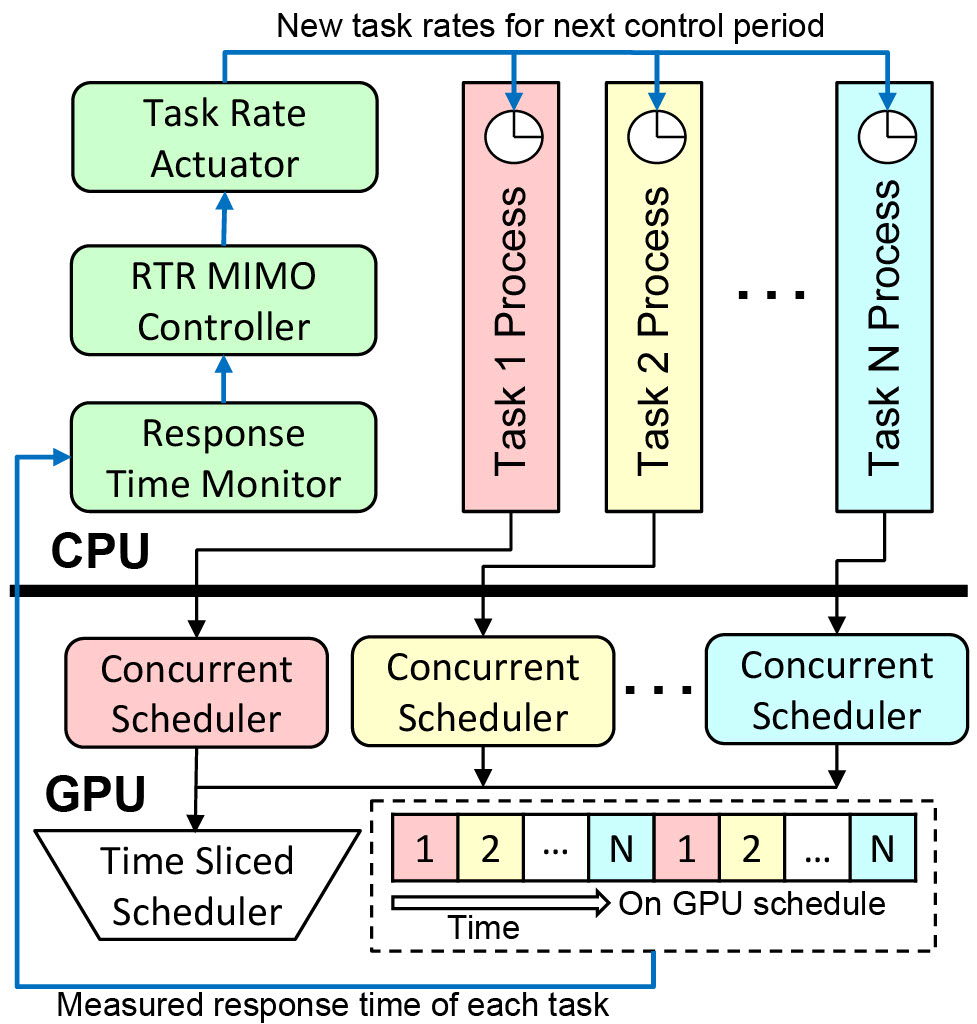
| Oct 01, 2025 | I presented my paper at ESWEEK (EMSOFT) 2025, where it was selected as a Best Paper Candidate. |
selected publications
- IPCCC
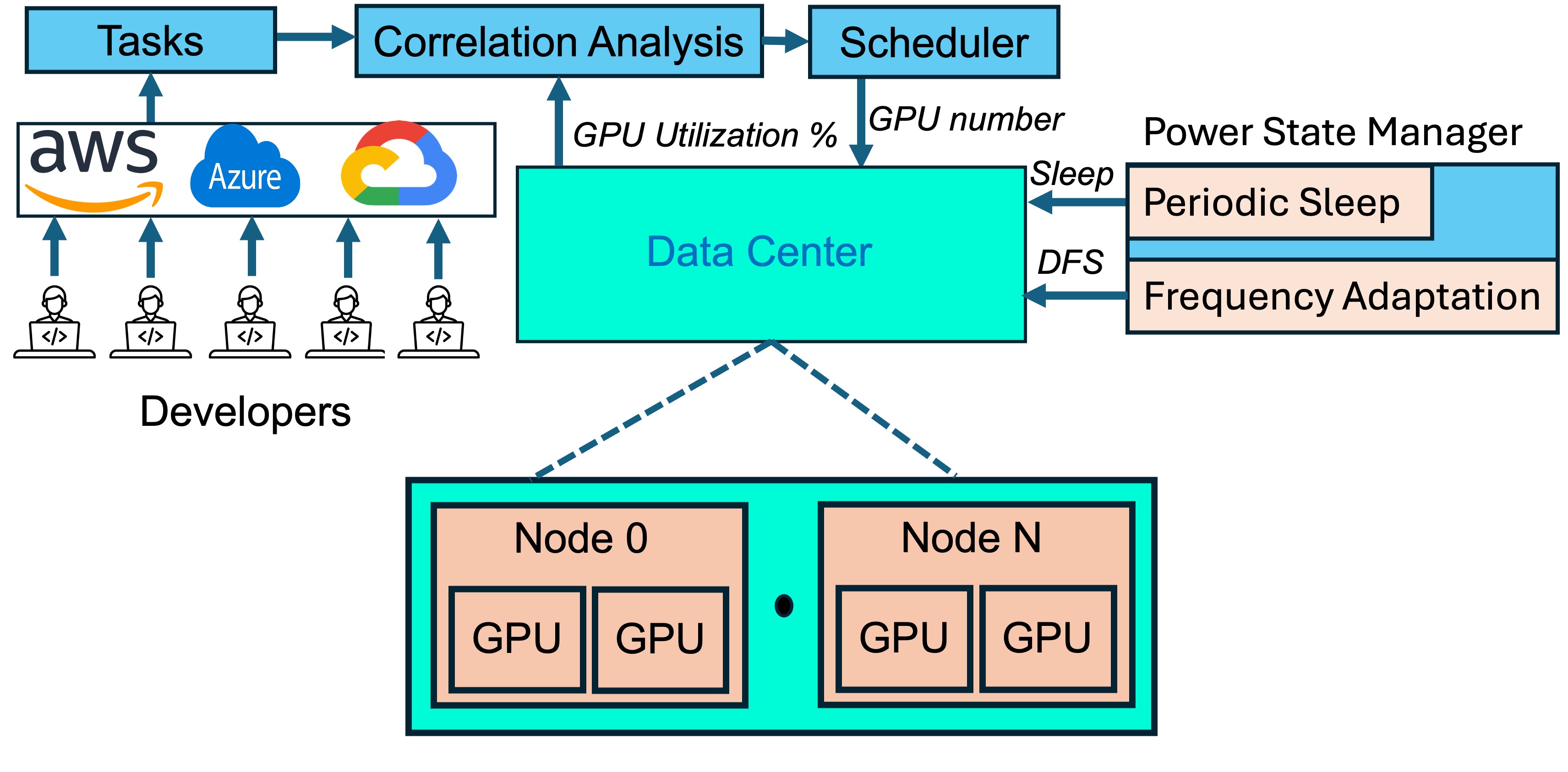
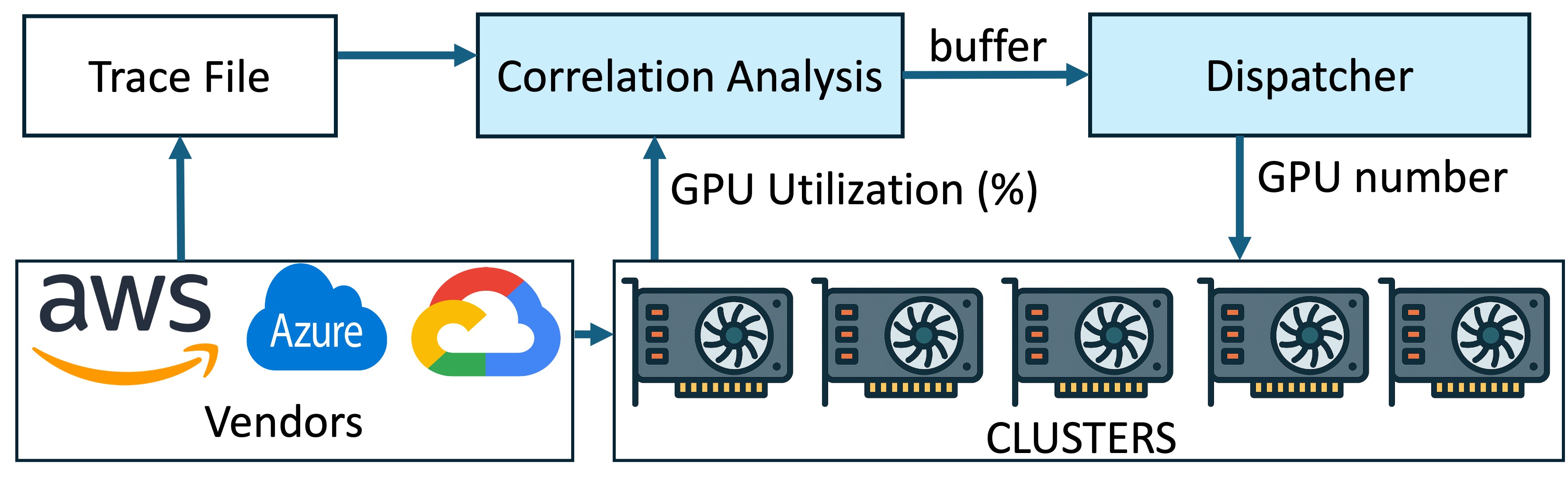 Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data CentersIn Proceedings of the 44th IEEE International Performance Computing and Communications Conference, 2025
Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data CentersIn Proceedings of the 44th IEEE International Performance Computing and Communications Conference, 2025