Latency-Controlled and Cost-Efficient GPU Scheduling for AI Workloads
Data centers often over-provision GPUs for online machine learning (ML) inference to handle bursty request arrivals. This over-provisioning leads to unnecessarily high capital expenses (CapEx).
This project aims to design a holistic management framework that handles bursty ML inference requests with strict latency guarantees while minimizing CapEx. The framework:
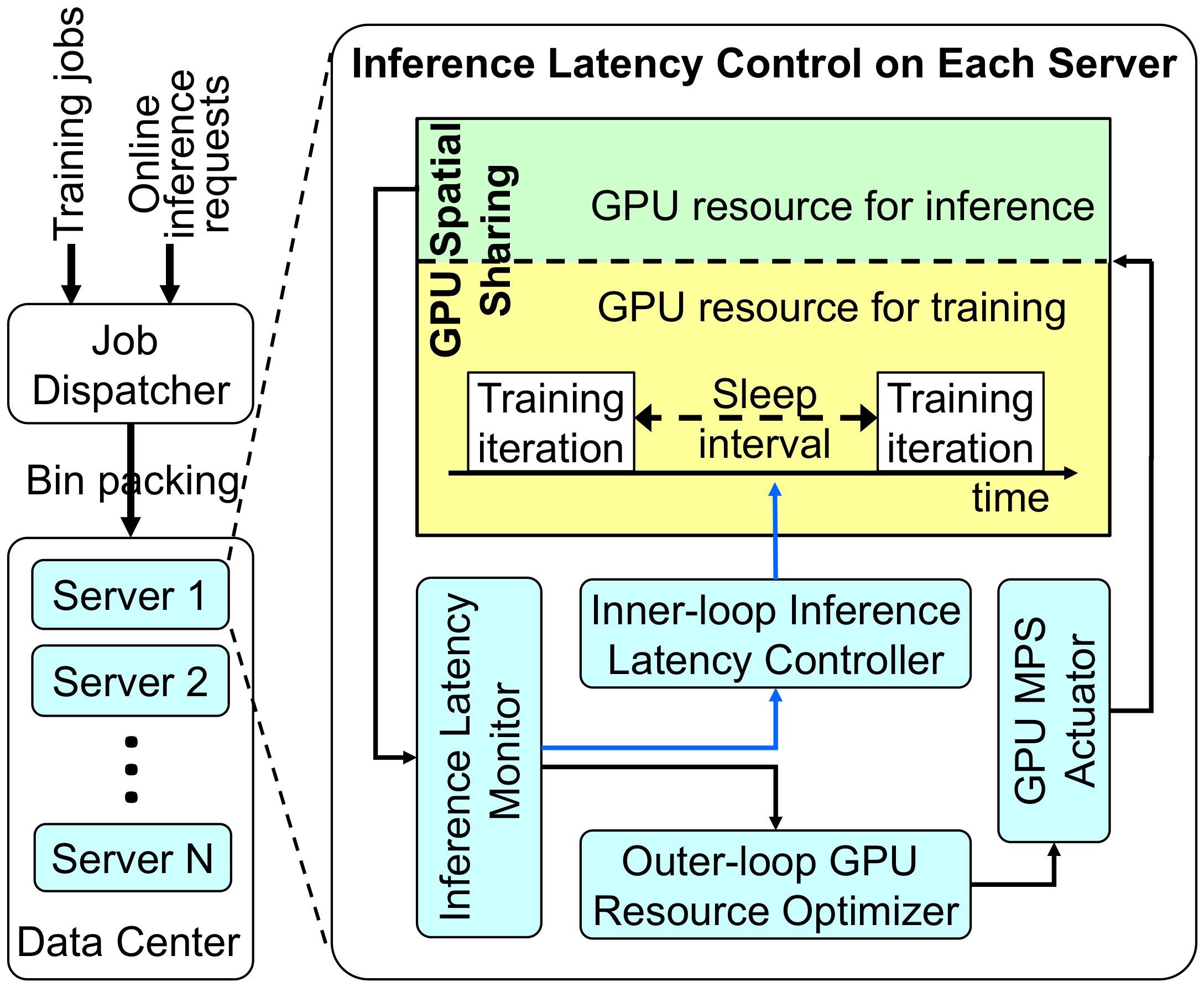
Co-locates ML inference and training workloads on the same GPUs with latency guarantees, improving overall GPU utilization. During bursts, GPUs are used mostly for inference; afterwards, capacity is shifted back to training, reducing the number of GPUs required.
Schedules and consolidates negatively correlated ML tasks onto shared GPUs to reduce resource contention and further lower CapEx.
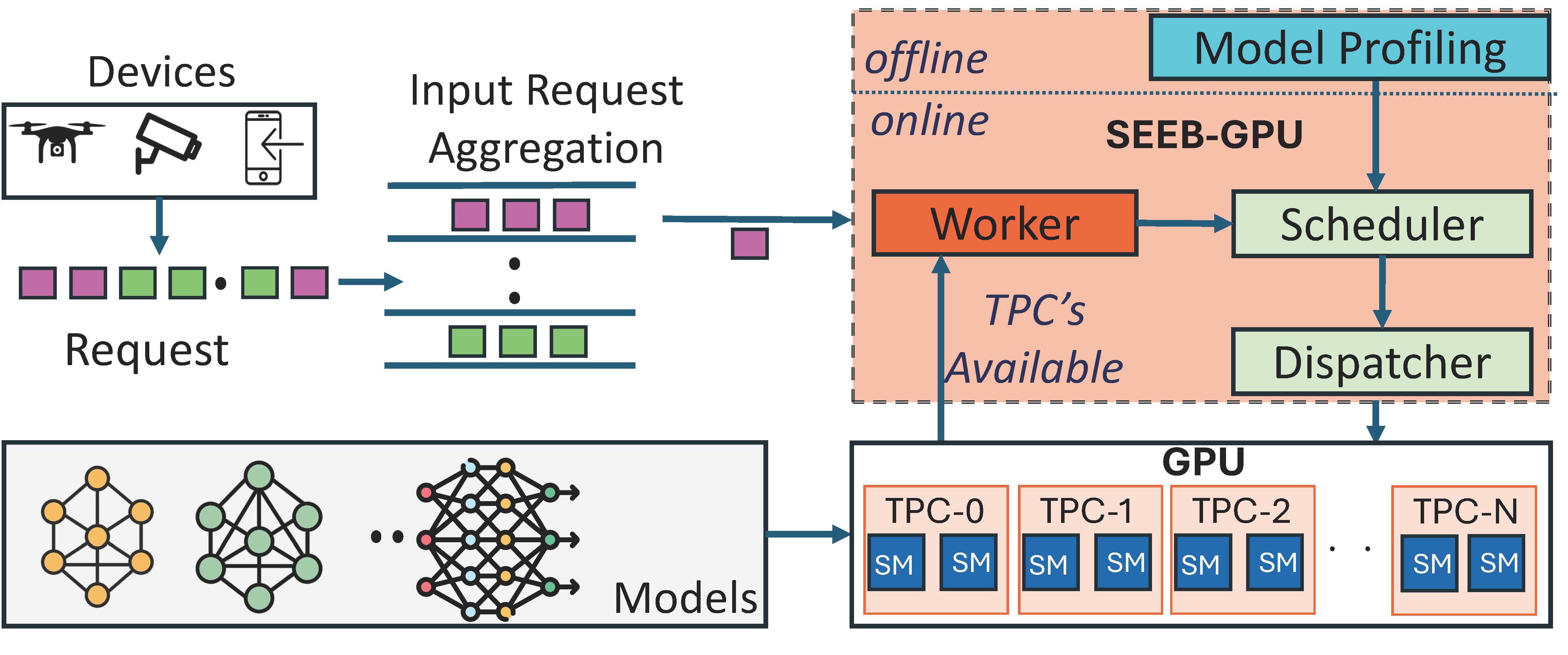
Uses resource-aware partitioning, batching, and TPC masking for GPUs in edge servers, where SLAs are strict and hardware resources are limited.
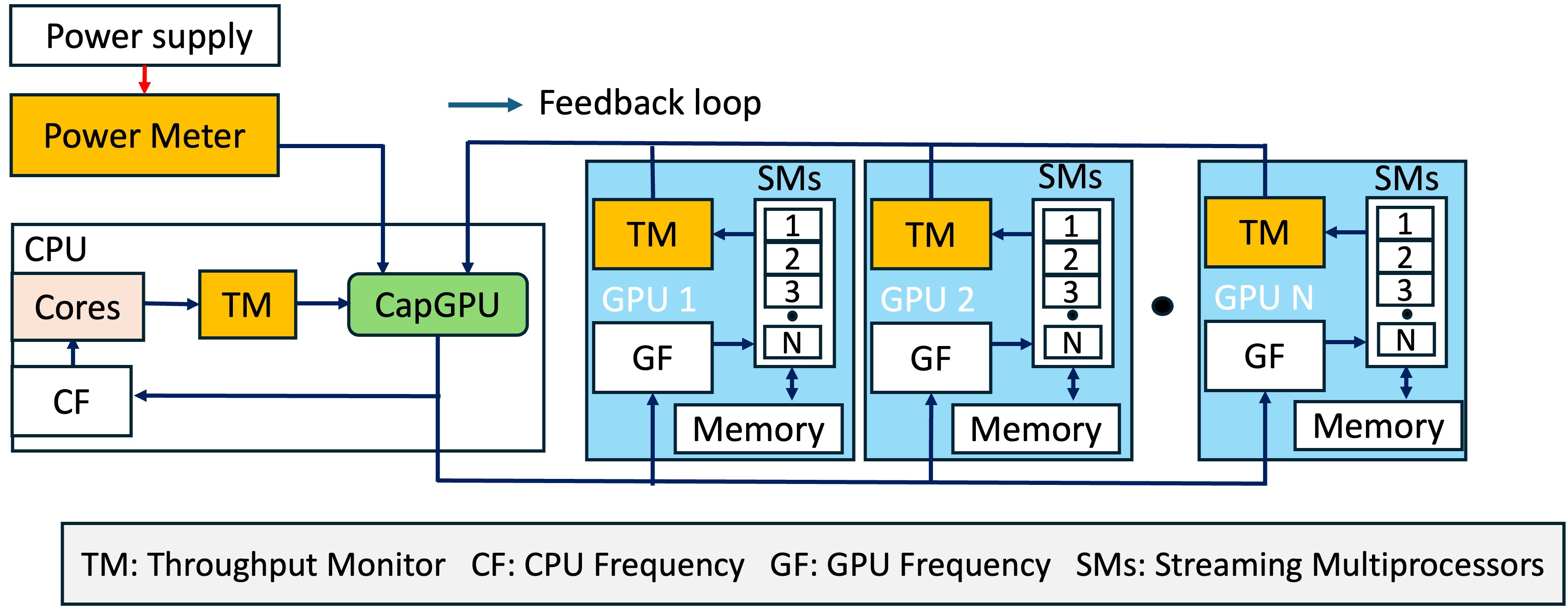
Applies power capping of ML servers used for AI inference to improve throughput while respecting both power and latency constraints.
Beyond GPU-level scheduling, the project also targets power and cooling CapEx. Instead of relying solely on expensive power infrastructure upgrades to handle occasional worst-case bursts, the framework exploits existing energy storage devices (common in modern data centers) to supply additional power during bursts. This allows data centers to avoid or defer costly facility upgrades while still meeting latency and reliability targets. . This enables data centers to safely handle large-scale ML inference bursts with explicit latency guarantees, while significantly reducing both compute and infrastructure CapEx. As ML cloud services continue to grow, the ability to run GPUs and servers at higher performance and lower cost has direct impact on both large providers and smaller ML/AI companies that depend on the cloud. Lower data center CapEx can translate into lower cloud bills and a lower barrier to entry for start-ups.
Publications from this project
This project has produced the following papers.
SEEB-GPU (SEC ’25) (Subramaniyan et al., 2025) Developed SEEB-GPU, an edge inference framework that jointly optimizes batching, early exits, and GPU partitioning to reduce latency by up to 15× while ensuring SLA compliance.
CorrGPU (IPCCC ’25) (Subramaniyan & Wang, 2025) Proposed CorrGPU, a correlation-aware GPU scheduler that dynamically pairs complementary workloads to reduce contention and lower CapEx by ≈20.9% in large-scale ML traces. –>
CapGPU (ICPP ’25) (Yuan Ma & Wang, 2025) Implemented CapGPU, a coordinated CPU–GPU power-capping strategy that improves inference throughput by 8–20% while maintaining latency SLOs under power constraints.
GPUColo (ICDCS ’24) (Chen et al., 2024) Built GPUColo, a co-location framework that enables training and inference workloads to share GPUs, saving up to 74.9% of GPUs and significantly reducing CapEx while meeting strict SLO requirements.
References
2025
SEC
SEEB-GPU: Early-Exit Aware Scheduling and Batching for Edge GPU Inference
Srinivasan Subramaniyan, Rudra Joshi, Xiaorui Wang, and Marco Brocanelli
In Proceedings of the Tenth ACM/IEEE Symposium on Edge Computing, 2025
@inproceedings{10.1145/3769102.3772715,author={Subramaniyan, Srinivasan and Joshi, Rudra and Wang, Xiaorui and Brocanelli, Marco},title={SEEB-GPU: Early-Exit Aware Scheduling and Batching for Edge GPU Inference},year={2025},isbn={9798400722387},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3769102.3772715},doi={10.1145/3769102.3772715},booktitle={Proceedings of the Tenth ACM/IEEE Symposium on Edge Computing},articleno={9},numpages={16},keywords={edge inference, GPU resource management, early-exit DNNs},series={SEC '25},}
IPCCC
Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data Centers
Srinivasan Subramaniyan and Xiaorui Wang
In Proceedings of the 44th IEEE International Performance Computing and Communications Conference, 2025
@inproceedings{CorrGPU,author={Subramaniyan, Srinivasan and Wang, Xiaorui},title={Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data Centers},year={2025},publisher={IEEE},url={https://par.nsf.gov/biblio/10652009},booktitle={Proceedings of the 44th IEEE International Performance Computing and Communications Conference},}
ICPP
Power Capping of GPU Servers for Machine Learning Inference Optimization
Srinivasan Yuan Ma and Xiaorui Wang
In The 54th International Conference on Parallel Processing, 2025
@inproceedings{CapGPU,author={Yuan Ma, Subramaniyan, Srinivasan and Wang, Xiaorui},title={Power Capping of GPU Servers for Machine Learning Inference Optimization},year={2025},publisher={IEEE},url={https://par.nsf.gov/biblio/10652010},booktitle={The 54th International Conference on Parallel Processing},}
2024
ICDCS
Latency-Guaranteed Co-Location of Inference and Training for Reducing Data Center Expenses
Guoyu Chen, Srinivasan Subramaniyan, and Xiaorui Wang
In 2024 IEEE 44th International Conference on Distributed Computing Systems (ICDCS), 2024
Today’s data centers often need to run various machine learning (ML) applications with stringent SLO (Service-Level Objective) requirements, such as inference latency. To that end, data centers prefer to 1) over-provision the number of servers used for inference processing and 2) isolate them from other servers that run ML training, despite both use GPUs extensively, to minimize possible competition of computing resources. Those practices result in a low GPU utilization and thus a high capital expense. Hence, if training and inference jobs can be safely co-located on the same GPUs with explicit SLO guarantees, data centers could flexibly run fewer training jobs when an inference burst arrives and run more afterwards to increase GPU utilization, reducing their capital expenses. In this paper, we propose GPUColo, a two-tier co-location solution that provides explicit ML inference SLO guarantees for co-located GPUs. In the outer tier, we exploit GPU spatial sharing to dynamically adjust the percentage of active GPU threads allocated to spatially co-located inference and training processes, so that the inference latency can be guaranteed. Because spatial sharing can introduce considerable overheads and thus cannot be conducted at a fine time granularity, we design an inner tier that puts training jobs into periodic sleep, so that the inference jobs can quickly get more GPU resources for more prompt latency control. Our hardware testbed results show that GPUColo can precisely control the inference latency to the desired SLO, while maximizing the throughput of the training jobs co-located on the same GPUs. Our large-scale simulation with a 57-day real-world data center trace (6500 GPUs) also demonstrates that GPU Colo enables latency-guaranteed inference and training co-location. Consequently, it allows 74.9 % of GPUs to be saved for a much lower capital expense.
@inproceedings{gpucolo2024icdcs,author={Chen, Guoyu and Subramaniyan, Srinivasan and Wang, Xiaorui},booktitle={2024 IEEE 44th International Conference on Distributed Computing Systems (ICDCS)},title={Latency-Guaranteed Co-Location of Inference and Training for Reducing Data Center Expenses},year={2024},url={https://ieeexplore.ieee.org/abstract/document/10630927},paper={Latency-Guaranteed_Co-Location_of_Inference_and_Training_for_Reducing_Data_Center_Expenses.pdf},pages={473-484},keywords={Training;Data centers;Graphics processing units;Machine learning;Throughput;Hardware;Servers;Machine learning;data center;inference;latency;GPU;co-location},doi={10.1109/ICDCS60910.2024.00051},}
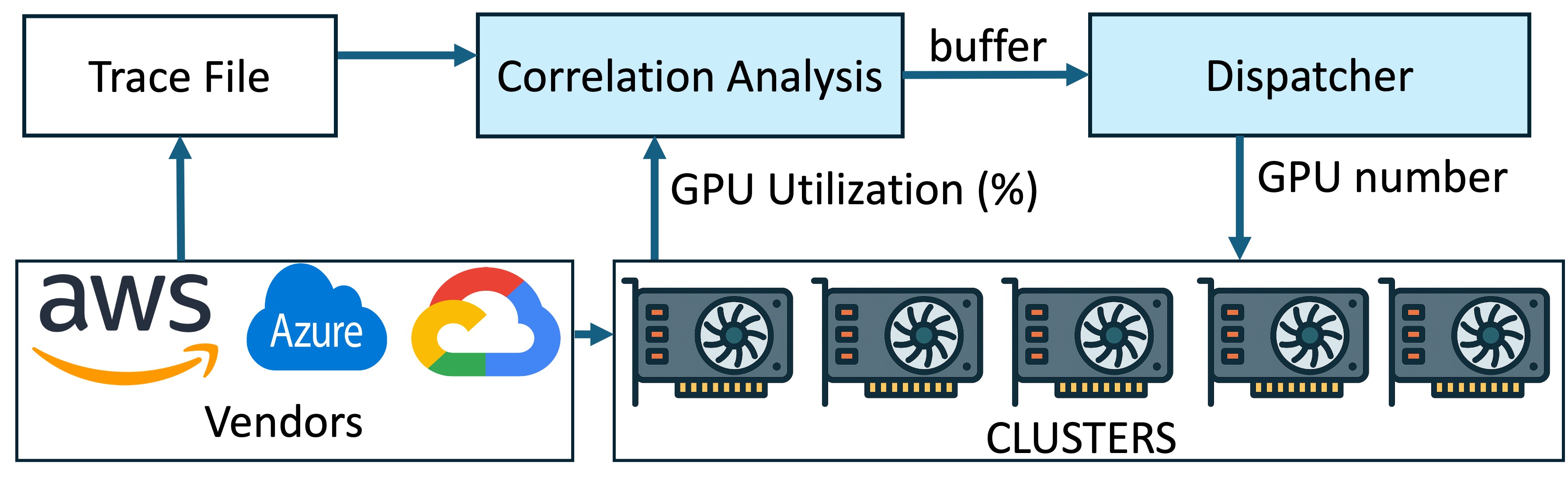 Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data CentersIn Proceedings of the 44th IEEE International Performance Computing and Communications Conference, 2025
Exploiting ML Task Correlation in the Minimization of Capital Expense for GPU Data CentersIn Proceedings of the 44th IEEE International Performance Computing and Communications Conference, 2025